
In an era where data is increasingly interconnected, the need for powerful graph analytics solutions has never been more critical. Enter TigerGraph Savanna, our next-generation cloud-native graph database designed specifically for graph analytics. TigerGraph Savanna offers a robust, scalable, and secure environment for provisioning, enabling organizations to gain valuable insights from their data and drive data-driven decision-making and innovation. In this blog, I will give you a guided tour of the design and features of Savanna which make it both powerful and user-friendly.
TigerGraph Savanna Architecture
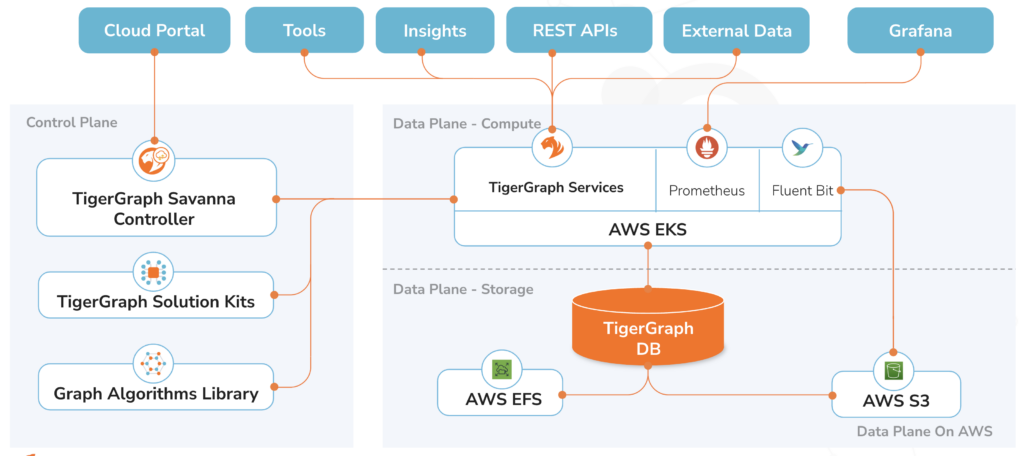
TigerGraph Savanna is engineered to handle complex queries and large datasets efficiently, leveraging cloud-native technologies to deliver high performance and reliability. The architecture comprises three main components: the storage layer, the compute layer, and the control plane.
Data Plane – Storage Layer
The Data Plane in TigerGraph Savanna is designed for efficient and high-performance persistent data storage. It features a distributed storage system where graph data is stored in Amazon S3 object store, ensuring data durability, availability, and cost-effectiveness. Amazon S3 is chosen for its scalable storage with high durability and availability, making it ideal for storing large volumes of graph data. Additionally, S3 is cost-effective for managing big datasets.
The system also uses Amazon EFS (Elastic File System) to store TigerGraph’s IDS (index data store). EFS is selected for its ability to provide scalable and high throughput file storage that can be accessed concurrently by multiple compute nodes with low latency. This is crucial for IDS, as these structures require fast and consistent access to support high-performance query execution and data retrieval.
By leveraging S3 for graph data and EFS for IDS, TigerGraph Savanna ensures a robust, scalable, and cost-effective architecture that meets the demands of complex graph analytics workloads. Savanna is designed to be cloud-agnostic. While the initial release runs on AWS, upcoming releases will include the option of running on Azure or Google cloud platforms, using their equivalent storage services.
Data Plane – Compute Layer
The compute layer is the core of the TigerGraph engine, optimized for complex query execution. It leverages parallel processing and in-memory computing to deliver fast query responses. The compute layer is managed using AWS’ Kubernetes service, to provide cloud-native elastic scaling, both horizontally and vertically, to address the compute needs of changing and possibly very large workloads with efficient and responsive performance.
Control Plane
The control plane in TigerGraph Savanna is the central management layer responsible for orchestrating the deployment, configuration, scaling, monitoring, and maintenance of TigerGraph instances. It automates routine tasks such as updates, backup and recovery, and security management, thereby reducing operational overhead and enhancing system resilience. The control plane automatically resumes and suspends compute resources based on workload demands and adjusts compute resources according to a predefined schedule, ensuring optimal performance and cost-efficiency. It continuously monitors system health and performance, providing real-time insights and alerts to facilitate proactive management. By enforcing robust security policies and compliance measures, the control plane ensures data protection and regulatory adherence. This comprehensive management approach enables efficient, secure, and scalable operation of the TigerGraph Savanna platform, making it well-suited for high-performance graph analytics.
Key Features of TigerGraph Savanna
TigerGraph Savanna is packed with features designed to provide a powerful and user-friendly environment for advanced graph analytics:
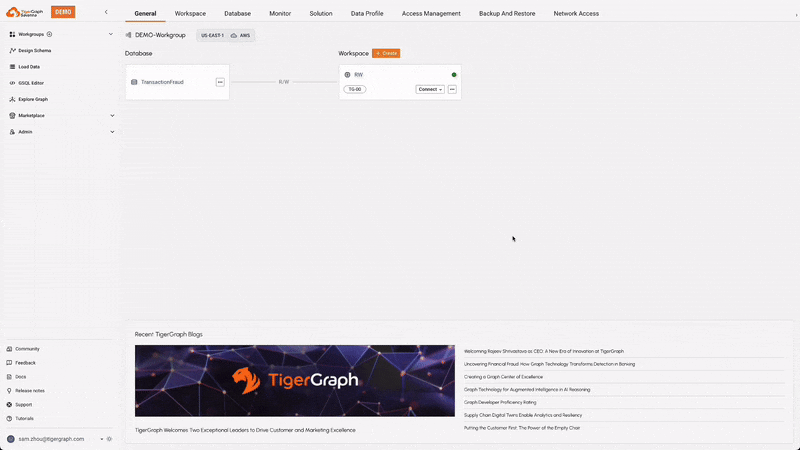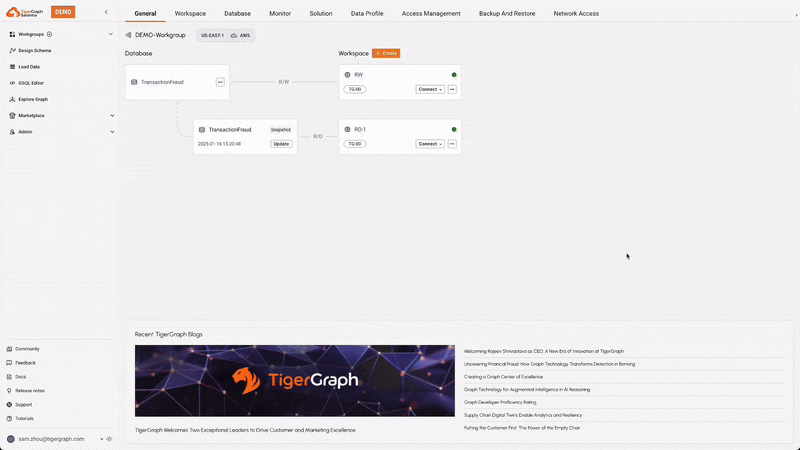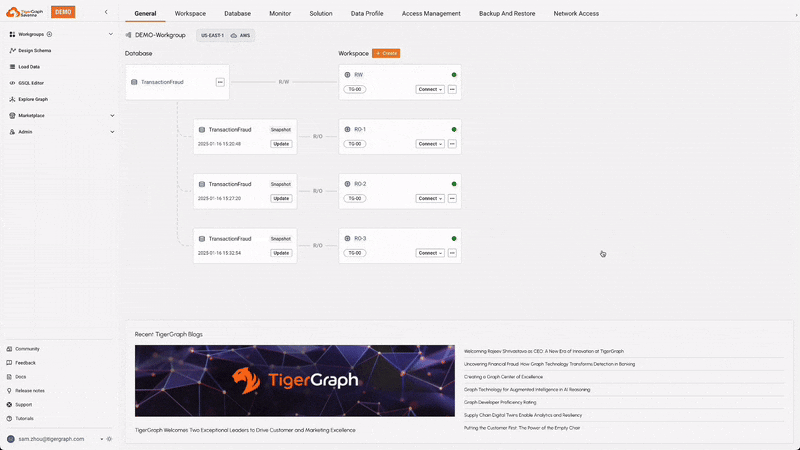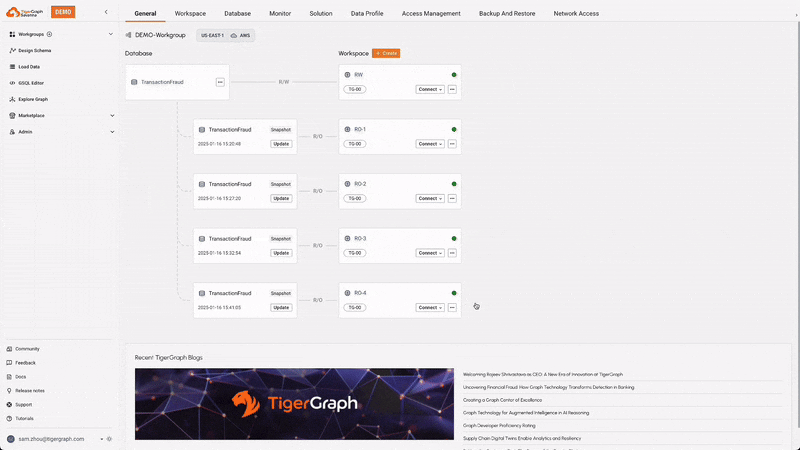
Compute-Storage Separation with RW and RO Workspaces
TigerGraph Savanna supports compute-storage separation, allowing for the creation of Read-Write (RW) and Read-Only (RO) workspaces. This separation enables optimized resource allocation and efficient handling of different types of workloads, facilitating easier upgrades, independent scaling, fault isolation, and cost-effectiveness.
Users can leverage this separation to obtain multiple benefits:
- Separate OLTP and OLAP traffic, reducing potential performance bottlenecks.
- Reserve Read-Write workspaces for transactional processing and real-time data updates.
- Use Read-Only workspaces to handle analytics and reporting tasks.
- Enhance their system availability and reliability by distributing workloads across specialized clusters.
Auto Suspend & Resume
This feature automatically suspends idle workspaces to save resources and costs, and resumes them when activity is detected. This ensures efficient use of resources without compromising performance, leading to cost savings, resource/energy efficiency, and reduced administrative overhead.
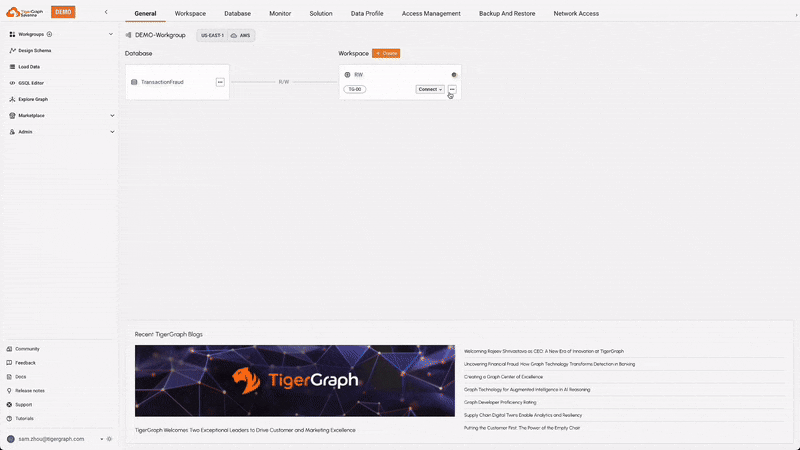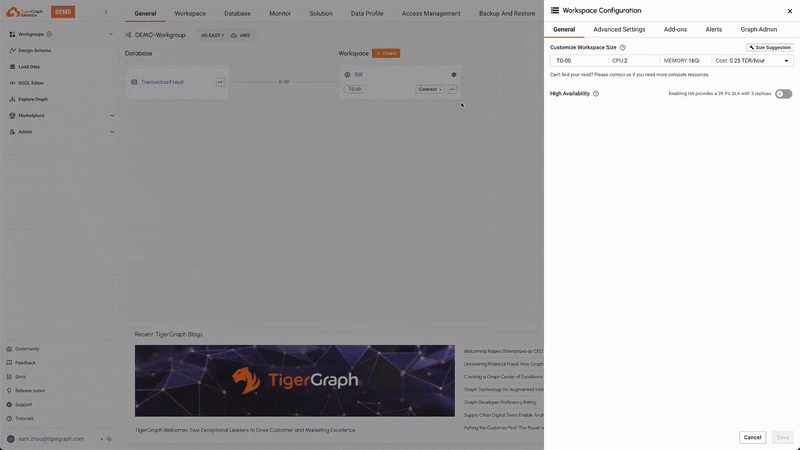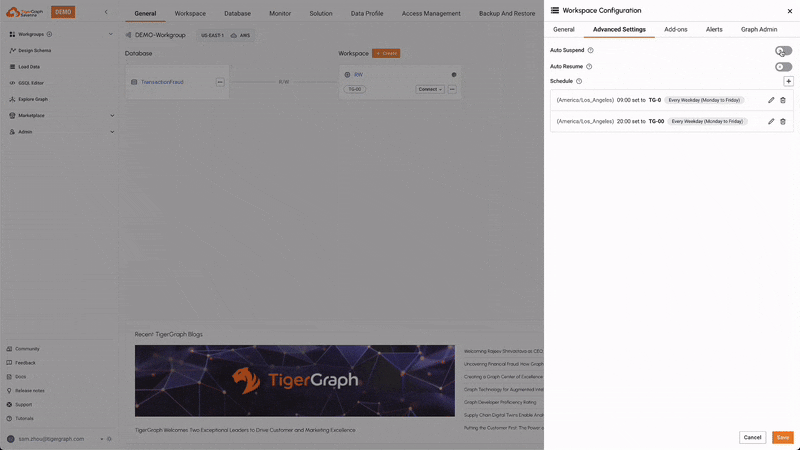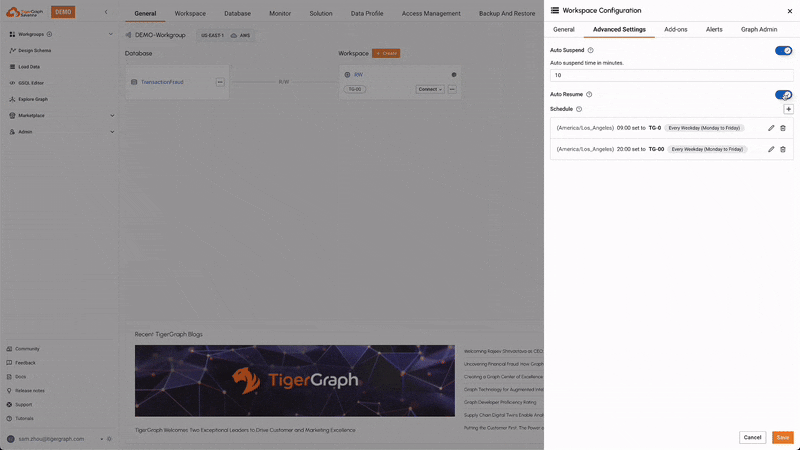
Scheduled Expansion & Shrink
Users can schedule the expansion and shrinkage of compute resources based on anticipated workload patterns. This ensures that the system can handle peak loads efficiently while minimizing costs during off-peak times, optimizing resource utilization.
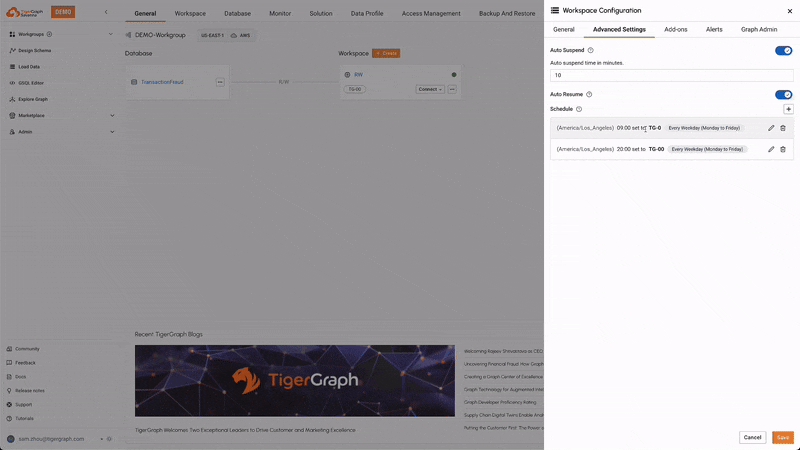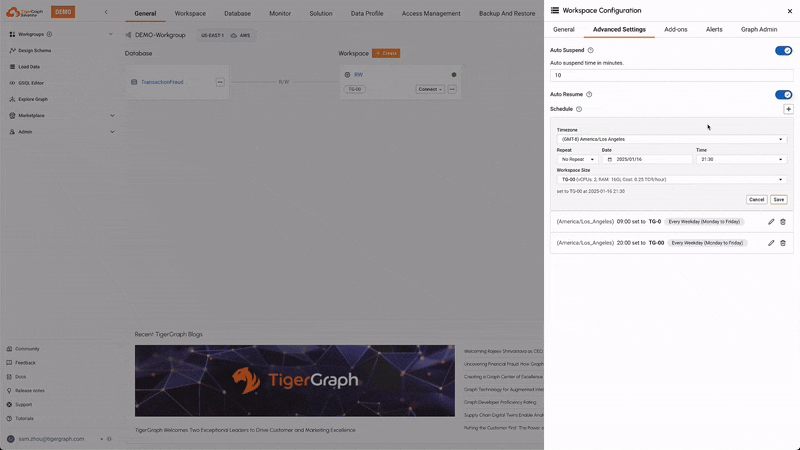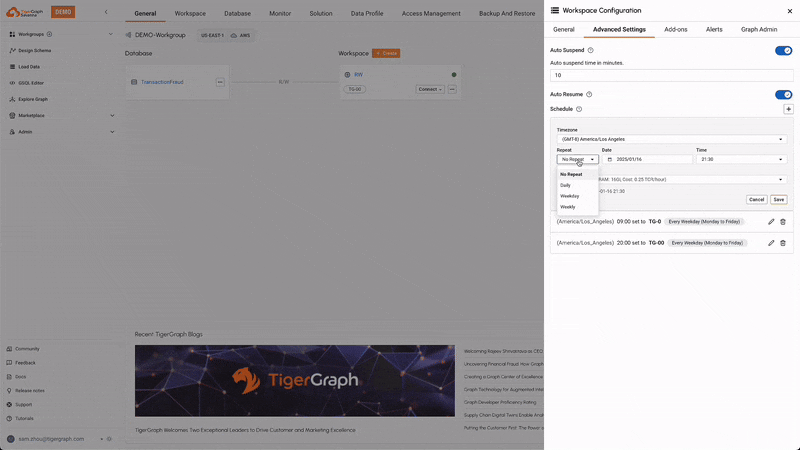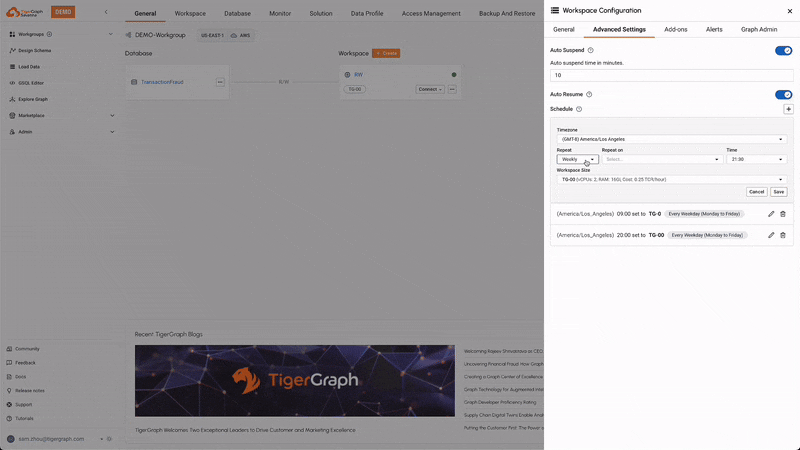
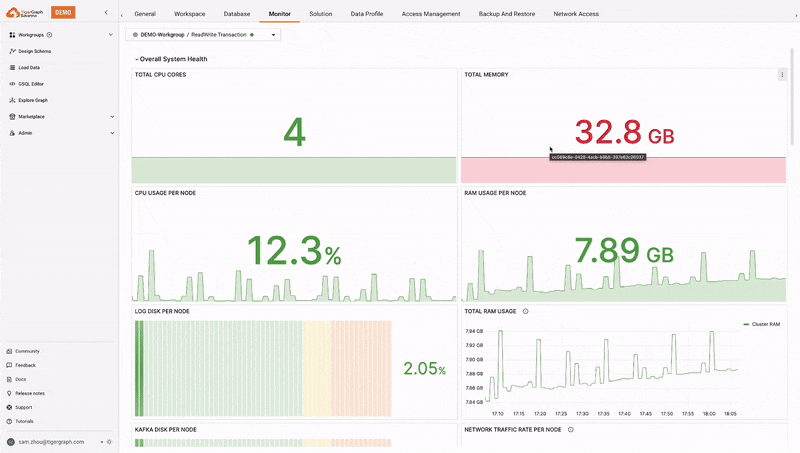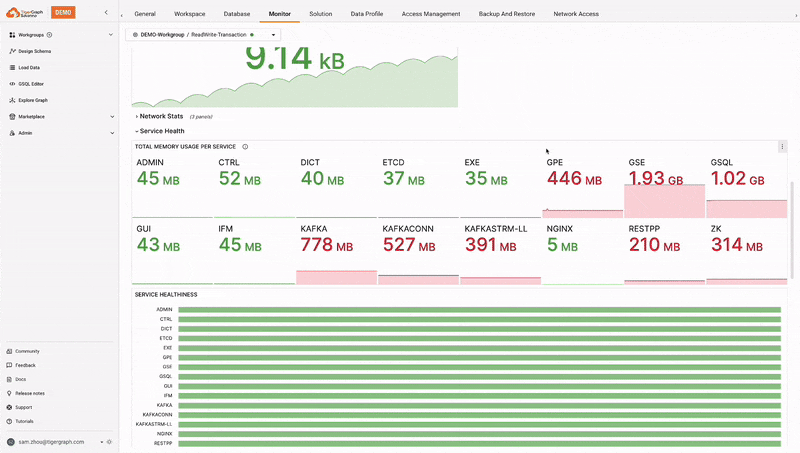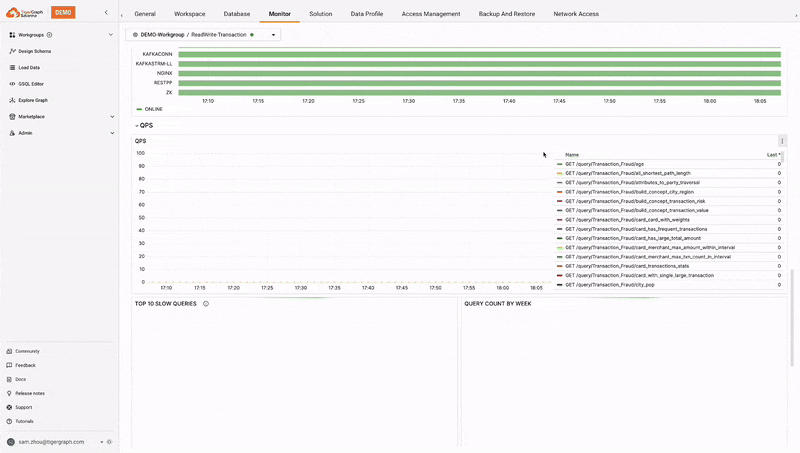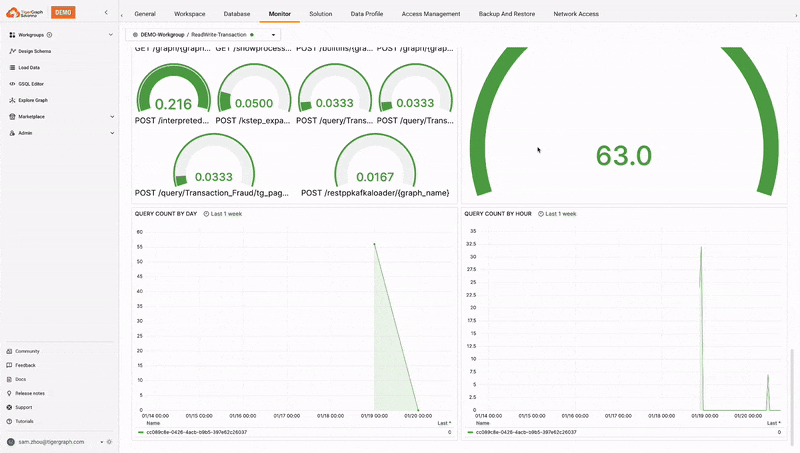
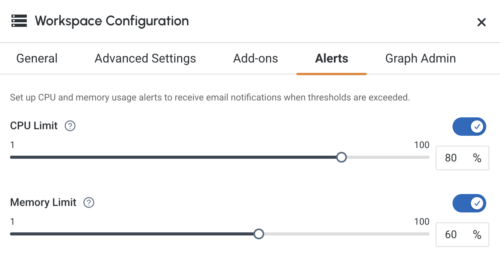
Monitoring & Alerting
TigerGraph Savanna provides real-time monitoring of workspaces, offering insights into usage, performance, and resource allocation. This helps in proactive management and optimization of resources. The system also continuously monitors the health of the TigerGraph Savanna environment and provides alerts in case of any issues, ensuring timely intervention and maintenance. This enhances visibility, efficient troubleshooting, proactive management, and timely interventions.
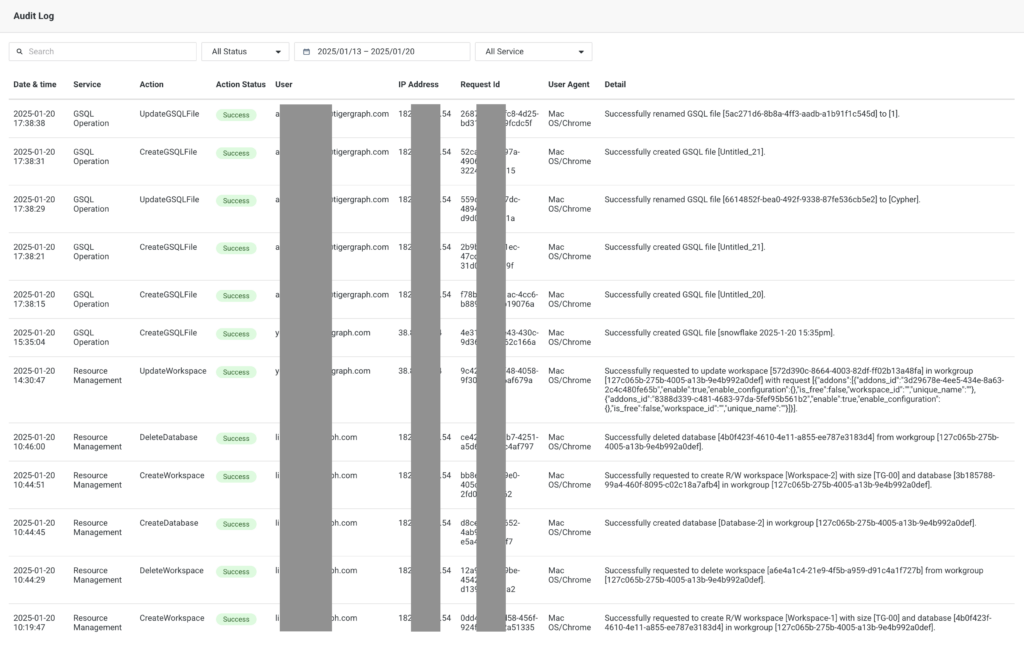
Log Management
Comprehensive log management features allow users to track and analyze audit logs and archive system logs. This enhances accountability, regulatory compliance, and allows for the archiving of data plane logs in S3.
Network Configuration
TigerGraph Savanna users (with an admin role) can define an IP allowlist for each workgroup, ensuring enhanced security, regulatory compliance, granular access control, and a reduced attack surface.

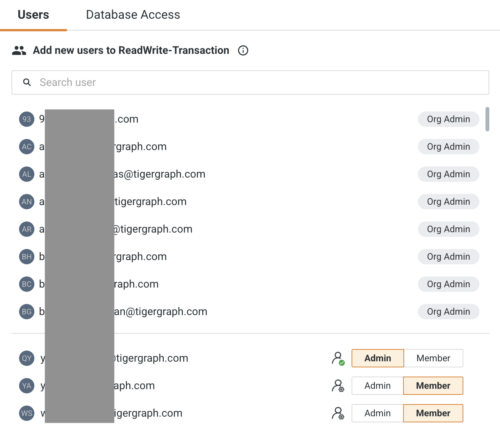
Easy User Permission Management
The platform provides robust tools for managing user permissions, allowing you to manage permissions from the users’ perspective or the resource’s perspective. This ensures that access to data and resources is controlled and secure, facilitating efficient permission management.

Data Ingestion
TigerGraph Savanna supports a rich list of data sources. Some data sources, such as AWS S3, Google Cloud Storage and Azure Blob Storage, can be set up with a handy no-code interface. For other sources, standard GSQL templates are available to help you quickly load your data into TigerGraph. If starting from an empty database, Savanna can examine that data you want to load and propose a graph schema as you go.
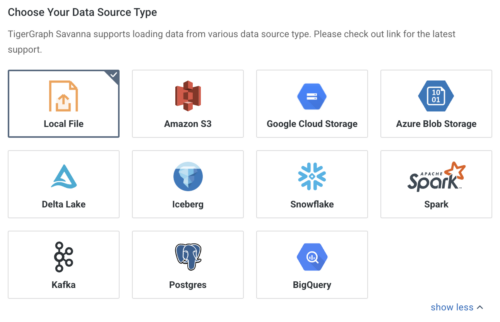
Data Export to S3
Users can export data from TigerGraph Savanna to Amazon S3, enabling easy data sharing and integration with other systems and workflows. This provides a scalable storage solution and enhanced data accessibility.
GSQL Editor & Schema Editor
The built-in GSQL Editor and Schema Editor provide intuitive interfaces for writing queries and designing graph schemas, streamlining the development process. Features include a graphic schema designer, tools for writing loading jobs, editing schemas in GSQL, executing across different workspaces, editing and running GSQL files, collaborating with colleagues, and sharing GSQL queries. Users can also write GSQL queries based on built-in graph algorithm templates, enabling quick application of advanced analytics techniques.
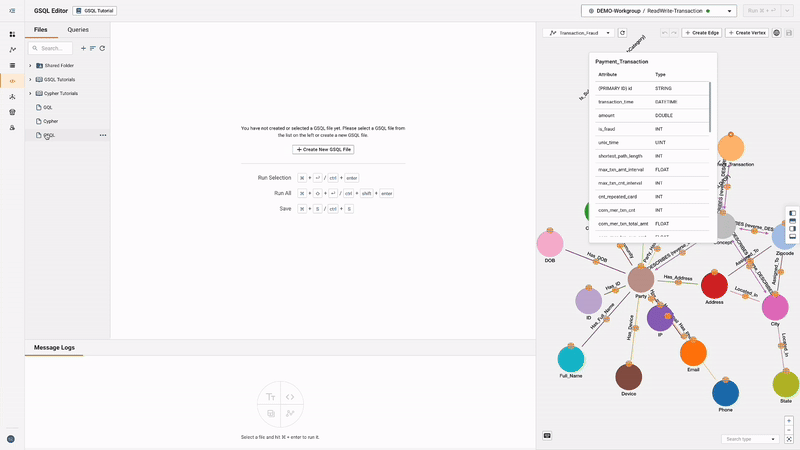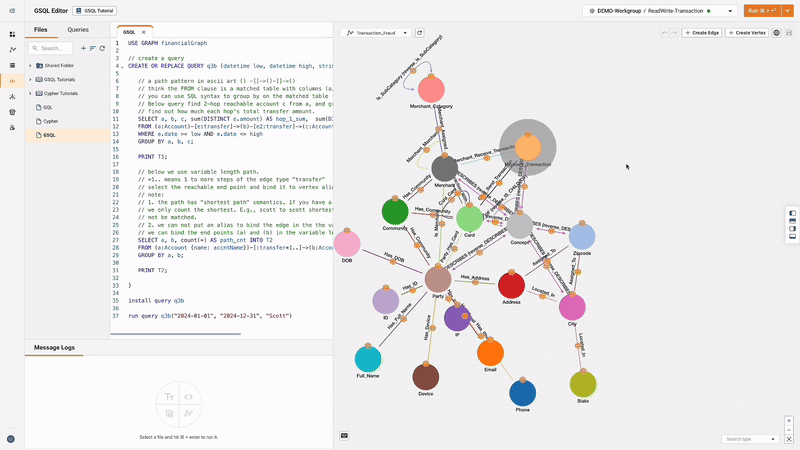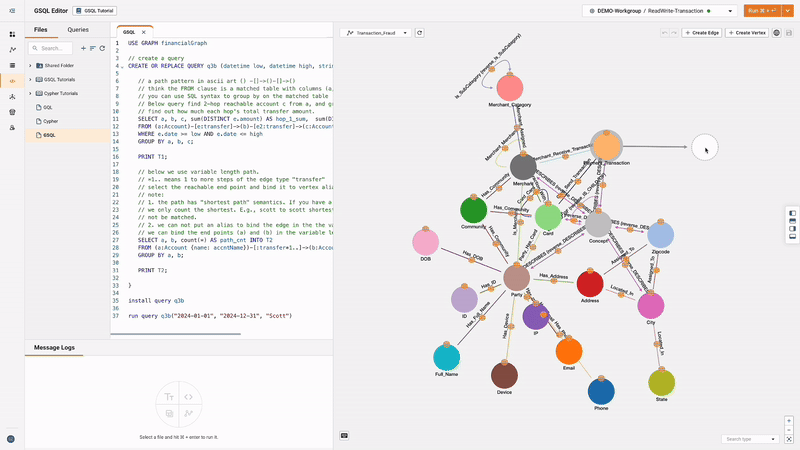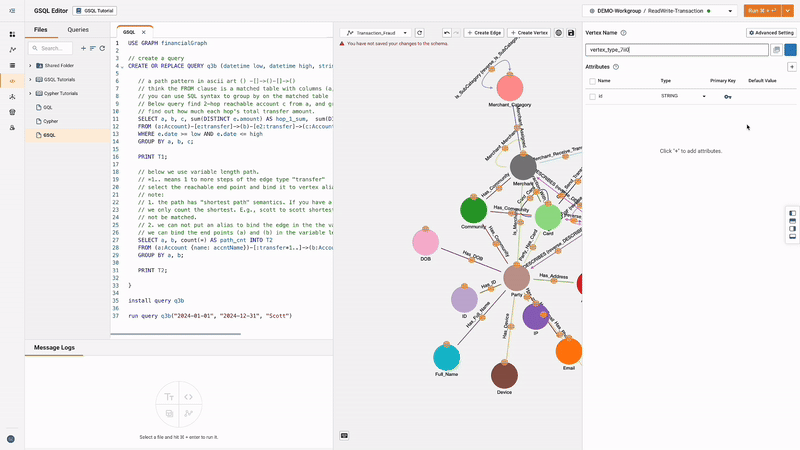
Solution Kits
TigerGraph Savanna offers pre-built solution kits, encapsulating TigerGraph’s expertise for mission-critical use cases, helping users quickly deploy and customize graph analytics solutions. Users can choose to jump-start with a solution when creating a workspace or add a solution to an existing workspace.
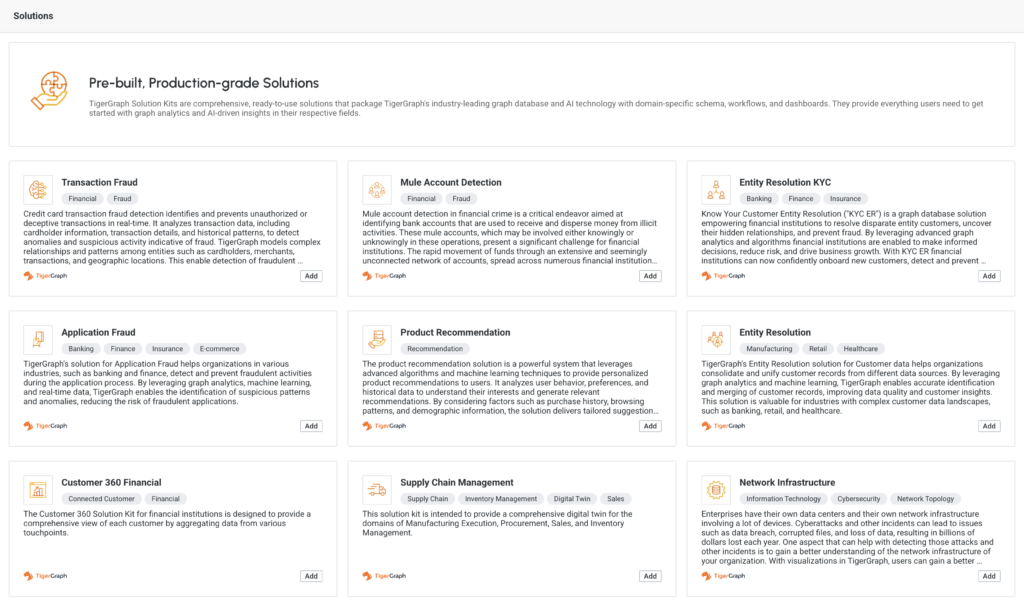
Auto Data Profile
This feature automatically profiles data as it is loaded, providing insights into data quality and structure, aiding in the preparation of data for analysis.
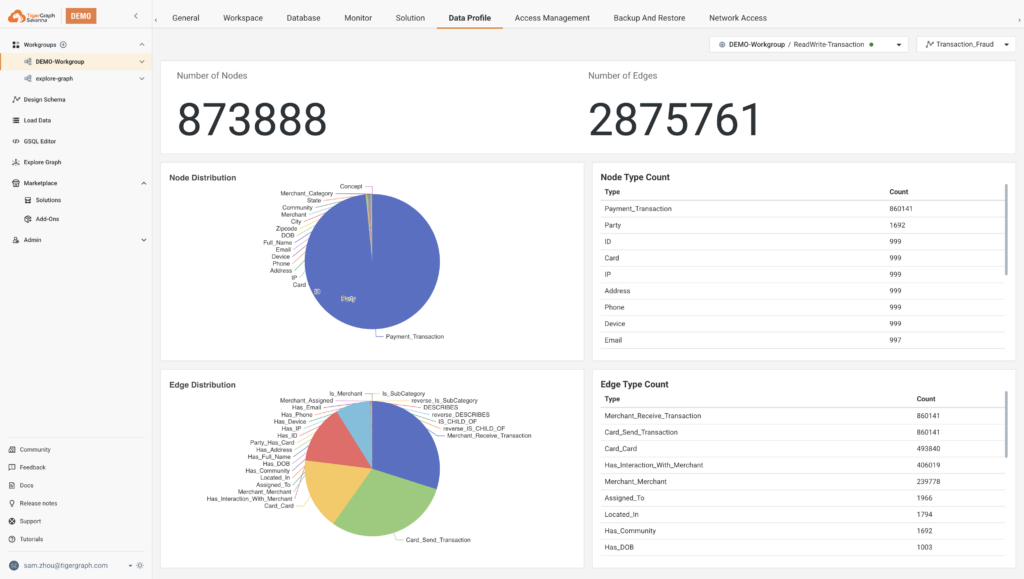
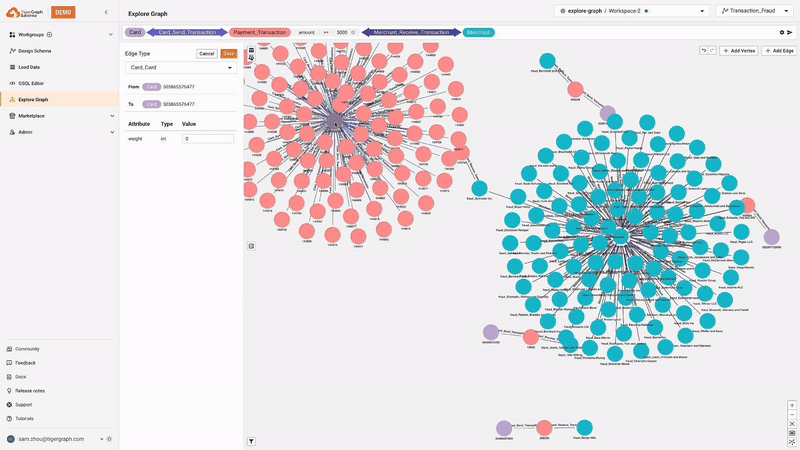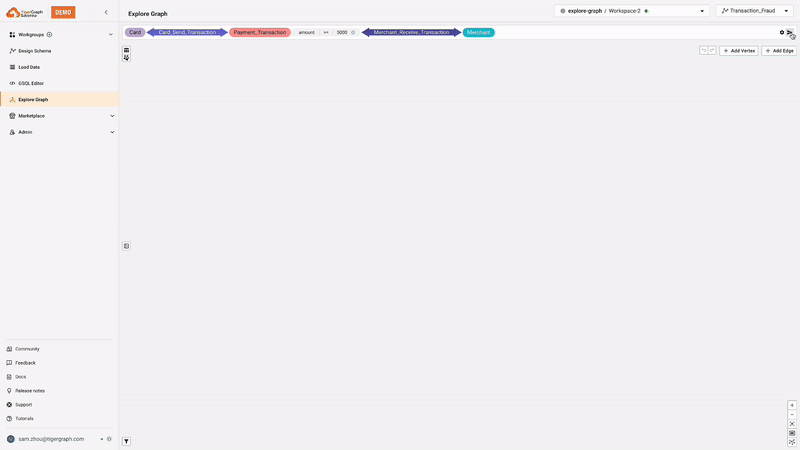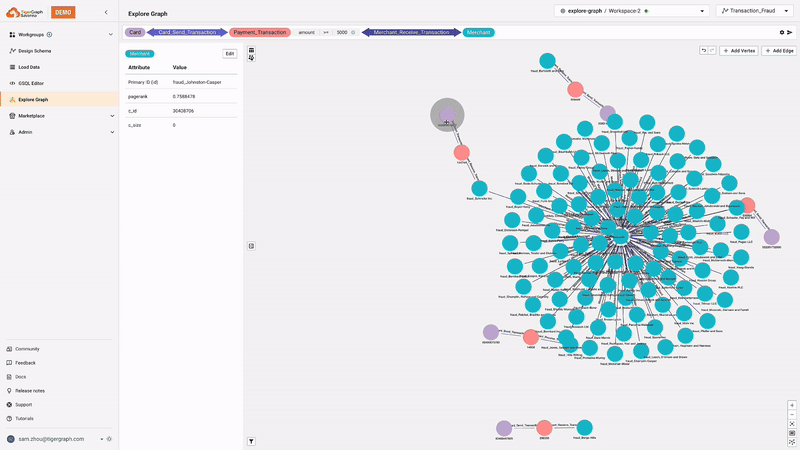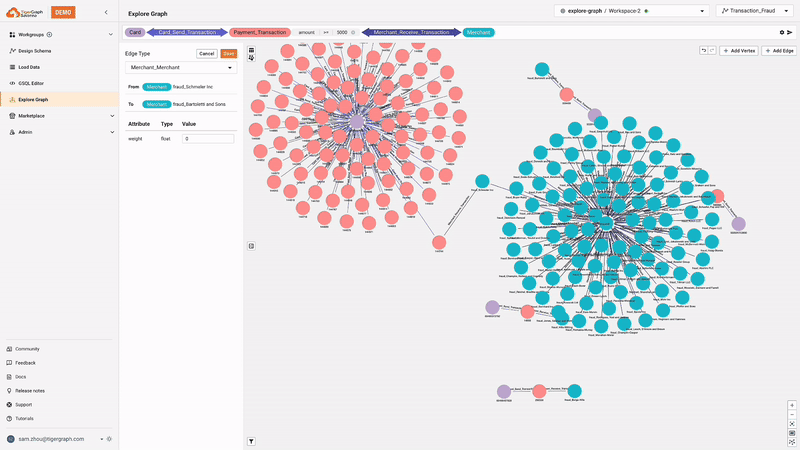
No-Code Graph Explorer
The no-code graph explorer allows users to interact with and analyze graph data without writing code, making graph analytics accessible to a broader audience. The graph explorer supports pattern search and installed queries, and allows users to explore neighbors, apply graph algorithms, and apply attribute-level filters.
These features collectively enhance the functionality, usability, and performance of TigerGraph Savanna, making it a powerful platform for graph analytics.
Getting Started with TigerGraph Savanna
Ready to dive into Savanna for easy-to-use and powerful cloud-native graph analytics? Click here to get started now!
To understand how TigerGraph Savanna differs from other TigerGraph offerings, see our comparison table. Unlock the full potential of TigerGraph Savanna by visiting our getting started guide.
